
Originally published at: https://www.ronenbekerman.com/intro-to-ai-its-gen-ai-baby/

A series about AI by Ronen Bekerman
It’s Gen-AI, Baby!
Ronen here from Gen-X saying that we are currently in Generation Alpha, which is damn close to being called Gen-AI if you ask me and see what’s happening online. Crazy, fascinating, scary, mind provoking, unethical, the next evolution. You name it, and you’ll be right.
let’s dive into the rabbit hole – blue pill or red pill?
Reading time: 7 min 15 sec
” Are You Living in a Computer Simulation? ”

Nick Bostrom
Philosopher, In his 2003 paper
I’ll be writing this article and follow-ups to it based on my experience as I go. Don’t expect any structure to it. Things change too fast anyways.
Getting philosophical about it
The idea that humanity might be living in a simulated reality gained significant attention in contemporary times due to the work of philosopher Nick Bostrom. In his 2003 paper, “Are You Living in a Computer Simulation?”, Bostrom presented the Simulation Hypothesis, which posits that we may be living in an advanced computer simulation created by a highly advanced civilization. This idea is not new, and you can trace it back to ancient philosophical concepts like Plato’s Allegory of the Cave, which can be interpreted as an early precursor to the idea of “living in a simulation” in the sense that it explores the concept of humans being trapped in an illusory or limited perception of reality.
 Allegory of the cave interpretation – Mixed Matte Painting + AI
Allegory of the cave interpretation – Mixed Matte Painting + AI
In the context of generative AI, these philosophical inquiries become particularly relevant. As generative AI models advance, they can create increasingly realistic simulations of various aspects of our reality, such as images, sounds, and even 3D environments. These AI-generated simulations may eventually become indistinguishable from the real world, leading us to question the authenticity of our experiences and the boundaries between simulation and reality.
There’s no need to venture into the realm of the Matrix to grasp the concept at hand. The mere presence of advanced text-based AI agents, voice AI agents, and visually stunning AI avatar agents operating freely in our digital environment is sufficient to illustrate this idea. Indeed, such technological advancements are already taking place, transforming our interactions and experiences in the virtual world.
Table of Contents
Getting the bad out of the way first
Generative AI has been a game-changer in numerous fields, but its rapid advancements have also raised several controversial topics and concerns. Some of the most prominent issues include:
- Deepfakes and misinformation.
- Intellectual property and copyright.
- Loss of jobs and skills.
- Bias and fairness.
- Ethical considerations.
- Environmental impact.
- Regulation and governance.
These controversial topics highlight the need for ongoing research, dialogue, and collaboration among various stakeholders, including AI developers, policymakers, and users, to ensure that generative AI, or what is now widely discussed as artificial general intelligence (AGI), is developed and deployed responsibly and ethically.
I’ll address these topics in follow-up posts.
Generative-AI, it is nice to meet you!
You know that feeling when you’ve got a super cool idea in your head, but you just can’t get it out for some reason? Like, maybe the process is a drag, you’re not in the right headspace, or the tools are just annoying. Well, guess what? This new AI stuff is changing the game big time! No more excuses – it’s time to unleash that creativity!
 Like this “Stunning Mid-Century Modern House in California, photo, 24mm tilt-shift CANON lens, golden hour, vibrant color, kodak vision 2383” as an example made with Midjourney v5
Like this “Stunning Mid-Century Modern House in California, photo, 24mm tilt-shift CANON lens, golden hour, vibrant color, kodak vision 2383” as an example made with Midjourney v5
Generative AI refers to a subset of artificial intelligence that focuses on creating new content, often based on a given dataset or a set of parameters. These AI models learn from existing data and generate novel output, such as images, text, music, or 3D models. They can augment human creativity or automate specific tasks, making them an exciting tool for artists and designers.
Some of the most popular generative AI techniques include Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Transformers. Each of these techniques has unique characteristics that can be harnessed for architectural visualization.
GANs
GANs consist of two neural networks, a generator and a discriminator, that work together to create realistic output. The generator creates new content, while the discriminator evaluates its quality. GANs have been used to generate photorealistic images, textures, and even 3D models, making them an invaluable tool for architectural visualization artists.
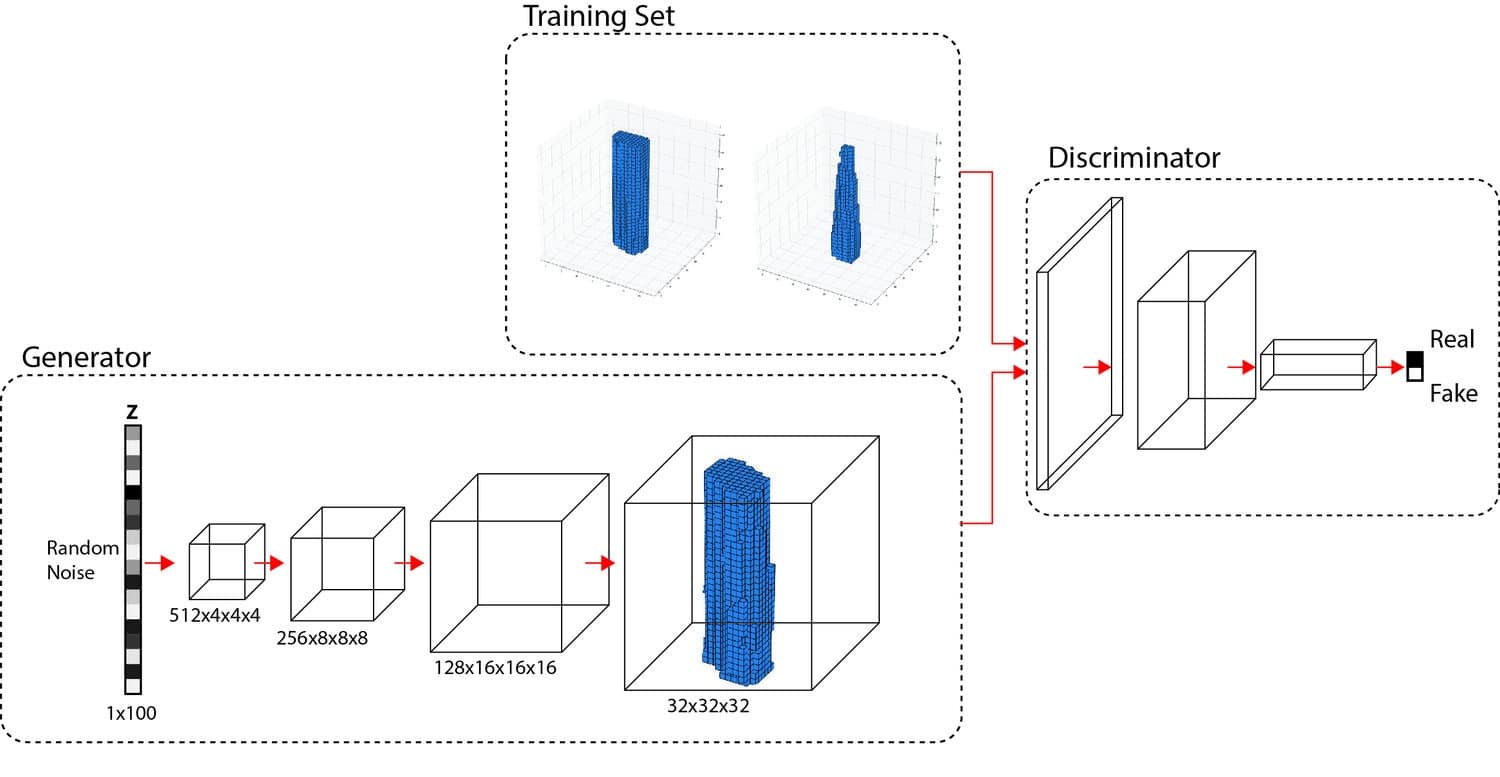 The diagram shows the generator and discriminator networks that make-up the 3D-IWGAN. Source: https://www.computationalarchitecturelab.org/3d-generative-adversarial-networks
The diagram shows the generator and discriminator networks that make-up the 3D-IWGAN. Source: https://www.computationalarchitecturelab.org/3d-generative-adversarial-networks
VAEs
VAEs are unsupervised machine learning models that learn to encode and decode data, enabling them to generate new content based on a given input. VAEs can be used to create variations of existing architectural designs, interpolate between different styles, or generate new design elements.
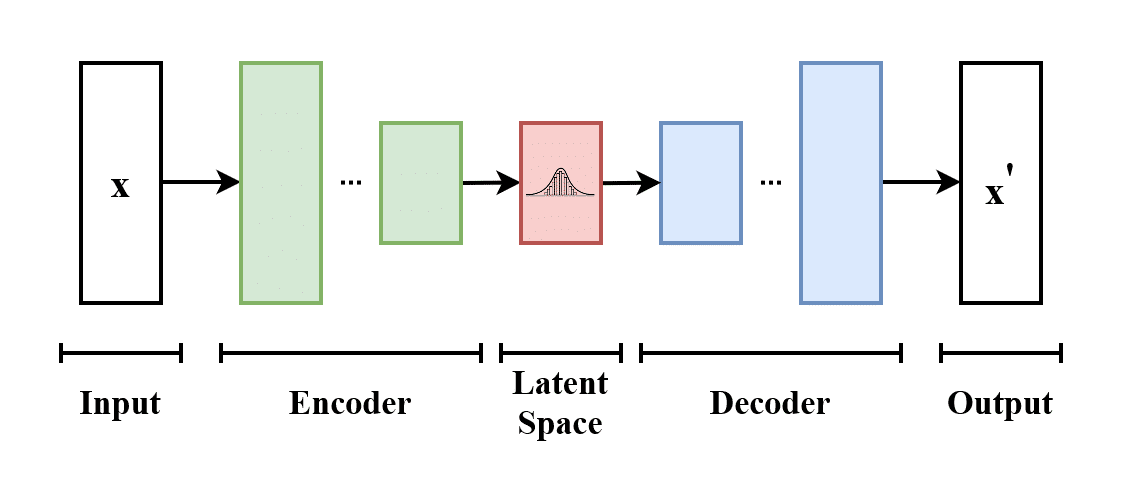 Variational autoencoder. (2023, April 3). In Wikipedia. https://en.wikipedia.org/wiki/Variational_autoencoder
Variational autoencoder. (2023, April 3). In Wikipedia. https://en.wikipedia.org/wiki/Variational_autoencoder
Transformers
Transformers are a type of deep learning model that has demonstrated remarkable capabilities in natural language processing and image generation. They can be used to generate textual descriptions of architectural concepts or create visually coherent images based on a given text input.
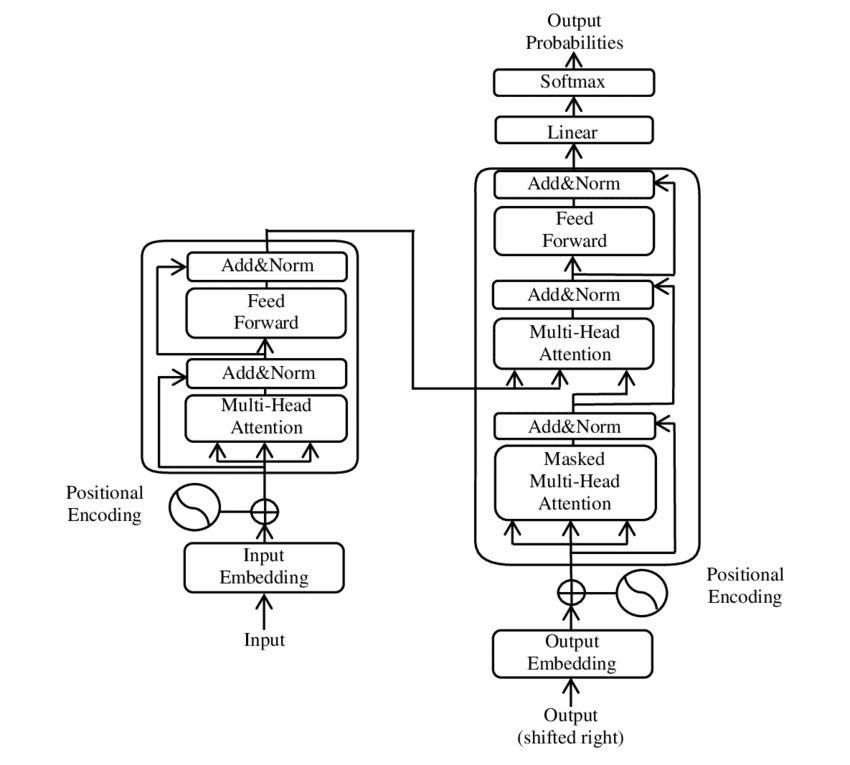 Transformer (machine learning model). (2023, April 19). In Wikipedia. https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)
Transformer (machine learning model). (2023, April 19). In Wikipedia. https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)
New tools of the trade
So far, I’ve been exploring and using DALL-E, Midjourney, and Stable Diffusion for generating images. I’ve added ChatGPT into the mix very recently as a way to get better at prompting.
“prompting” refers to providing an initial input or a seed to an AI model, which then guides the model to generate new content based on that input. The prompt serves as a starting point for the AI model, shaping its response or output in a specific direction depending on the desired outcome. You can also use images as a prompt or as part of a prompt.
Prompting seems to be a rising skill, with talks about “prompt engineer” being a new job position created by AI already. Sure enough, you can already see such job posts published online.
 Taking the previous “Stunning Mid-Century Modern House in California” for a spin with ChatGPT to be more methodical about the results
Taking the previous “Stunning Mid-Century Modern House in California” for a spin with ChatGPT to be more methodical about the results
DALL-E
The first generative AI tool I encountered left me in awe. I was particularly impressed by its innovative “generation frame” feature, which resembles inpainting capabilities found in other tools. This remarkable feature enables users to extend an image infinitely, one square at a time, by utilizing various prompts—a truly captivating and unique experience.

And below you can see the result after several generation frames as I was aiming for an “epic” scene! Each new square with a prompt to generate the specific things I wanted in the “tile”.

Midjourney
The most exceptional generative AI tool I’ve used, in terms of output quality, has undergone significant improvements with the release of Version 5. This update has not only enhanced the overall output quality but also introduced innovative features such as “describe,” “blend,” and more. In comparison to Version 4, the new iteration produces strikingly photorealistic results, surpassing DALL-E 2, which I previously considered superior in this aspect. The advent of Version 5 has truly raised the bar for generative AI tools.
Below are the very first images I’ve made with Midjourney a year ago!
And below a few from the recent month!
Stable Diffusion
Boasting unparalleled flexibility and the ability to run on your own hardware, this particular generative AI tool offers a wealth of plugins, addons, and customization options for controlling the output, most notably through control nets.
 bottom row is what you get with just the dog image + a prompt. Top row is when you use a control net on the dog image! Now translate that to architecture 🙂
bottom row is what you get with just the dog image + a prompt. Top row is when you use a control net on the dog image! Now translate that to architecture 🙂
I primarily use this tool for intentional generation, taking advantage of the numerous models available online or even training it myself. Furthermore, it paves the way for creating animations, an area I’m particularly eager to explore in the near future.
The art of the prompt
Or the modern-day equivalent of the California Gold Rush of the 1800s.
You can joke about it all you want, but you need the [blank] prompt to get the desired result. And I keep it blank since it is not “right,” “correct,” or “best,” to name a few options. It is undoubtedly something, but that is for you to figure out!
Much like digging for gold, the quest for success has remained the same: a combination of hard work, skill, and a bit of luck.

That was the point I decided to bring in ChatGPT. I’ve been conjuring up countless prompts on my own before that, but I decided to get more methodical about it.
Taking it for a spin in the #ChatGPT + MJ process I’m exploring. My aim is to make this look more like an architecture photographer professional has taken the photos. You can indicate a known photographer for the style (not sure how ethical that is, but it works) to get very interesting results.
This is totally text-to-image, and MJ decides about the output, but there is a lot you can do in a prompt to direct it.
Midjourney is far better (in my tests) than stable diffusion for generating the first result.

And an “old” black and white photo look to it!

More examples
The first (left) one is the result. The second one is an old matte paint I did. The process was feeding the matte paint to midjourney new describe feature to get some prompts, taking that to ChatGPT for making a better version to feed back to midjourney, using the original image in the prompt as well, upscaling a favorite result and back to photoshop for final edits. Overall “title” of the image remains the same for me.
For the “Plato’s Cave” image above, I employed a similar process. Crafting the image based solely on a text prompt proved to be quite challenging. To overcome this, I initially “guided” the AI using image blends and subsequently created a rough matte painting to serve as an image prompt. This approach facilitated the generation of the desired outcome.
What’s next?
In upcoming posts, I’ll delve deeper into the challenges and concerns I mentioned earlier while also providing more technical insights on setting up various tools and techniques for generating images. Additionally, I’ll continue to share my ongoing exploration of this groundbreaking technology.
Currently, I’m conducting experiments using AutoGPT and ChatGPT Agents and animations with stable diffusion. I’m also working on automating ArchViz-related tasks, such as Day-to-Night conversions, face replacement for 3D characters, complete character replacement or population, and even full image creation – from concept to the final result – based on a 3D model. Stay tuned for more exciting updates and discoveries!

Polytown Media LTD
© All Rights Reserved 2022

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}